大家好,大兵又来给大家分享干货了,本篇文章教大家如何使用Robots工具及如何正确设置蜘蛛的抓取范围。


一、了解什么是robots文件
1、什么是robots文件?
robots文件主要用于指定搜索引擎蜘蛛spider在网站里的抓取范围,用于声明蜘蛛不可以抓取哪些网站资源及可以抓取哪些网站资源;
2、robots.txt文件怎么写?
robots.txt文件可以包含一条或多条记录,以空行分开,通常以User-agent开始,后面再加上Disallow或者Allow命令行,不需要的命令行也可以使用#进行注解,如下详情所示:
User-agent:用于描述允许哪些搜索引擎抓取该网站,例如“*”号代表所有搜索引擎都可以抓取,“Baiduspeder”只允许百度蜘蛛抓取,“Googlebot”只允许谷歌蜘蛛抓取,“Bingbot”只允许必应蜘蛛抓取。
Disallow:用于描述不希望搜索蜘蛛抓取的URL链接或结构目录,可以是一条完整的URL链接,也可以是一个URL结构目录,但不能是空格,空格表示此网站禁止所有搜索引擎抓取,以Disallow开头的URL链接或结构目录是不会被蜘蛛抓取的。
Allow:正好与Disallow相反,该条robots命令表达的意思是允许搜索蜘蛛抓取URL链接或目录,因此以Allow开头的URL链接或结构目录是允许蜘蛛抓取的。
如果网站根目录没有robots.txt文件或者为空,那么,表达的意思是就是此网站所有链接和目录,对所有搜索引擎都是开放的。
注意:大家在撰写robots.txt文件时,要注意URL链接或结构目录名称的大小写,否则robots协议不会生效。
网站robots.txt文件举例:
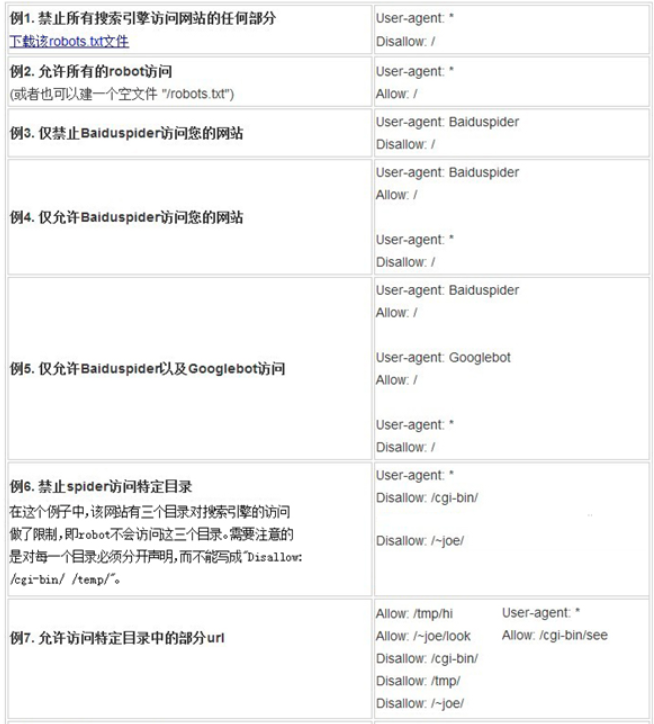
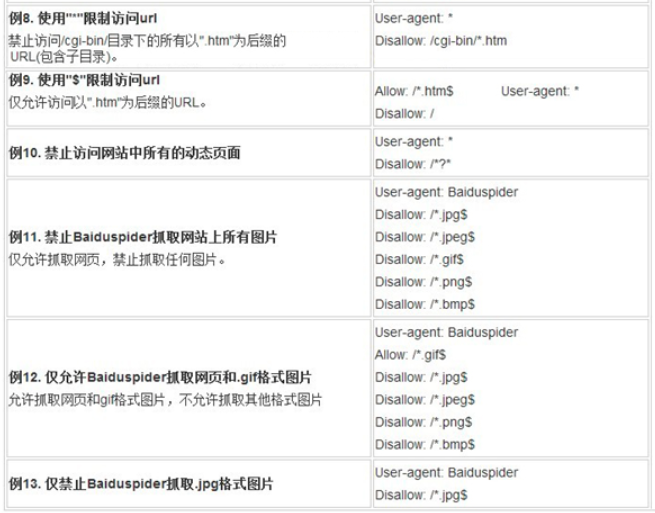
3、robots.txt文件放在什么位置?
网站robots.txt文件通常放于网站根目录下,网站对应robots.txt文件URL地址如下所示:

想要知道什么是网站robots文件,可参考《robots标签是什么意思?》。
二、如何使用Robots工具
1、Robots工具的作用?
可使用百度站长平台Robots工具,对网站robots.txt文件进行校验、更新等操作,查看网站robots.txt文件是否生效或是否有错误;
2、使用Robots工具的注意事项?
百度站长平台Robots工具目前只能检测48K以内的文件,所以站长们要注意,网站robots.txt文件不要过大,新的robots文件创建更新后,蜘蛛不会马上调整抓取方向,是逐步对网站robots.txt文件抓取规则进行更新的。
3、网站robots.txt文件中已经设置了禁止蜘蛛抓取的内容,为什么还会出现在网站索引数据中。
可能有以下两个方面的原因:
1)网站robots.txt文件不能正常访问,这种情况,我们可以使用站长平台Robots工具进行检测,检测robots文件是否可以正常访问;
2)新创建或新更新的robots.txt文件还没有生效,蜘蛛执行的抓取原则还是未更新前robots.txt文件,新的robots文件生效周期为1~2周。
4、Robots工具校验提示
网站Robots如果有错误,则会出现以下提示:
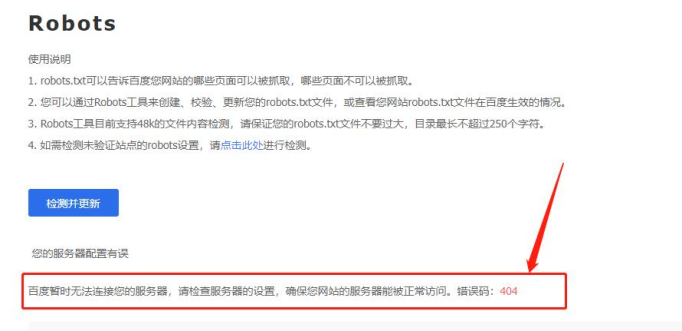
网站Robots文件,出现以上错误,则有可能是以下原因:
错误码404,表示网站robots文件不能正常访问;
错误码301,表示网站robots文件存在跳转关系;
错误码500,表示网站robots页面访问失败;
如果你网站的Robots文件也有出现以上错误代码,建议根据以上情况进行自查,重新提交校验。
5、robots文件误封禁了网站,如何处理?
1)马上修改网站robots文件,将封禁改为允许;
2)使用站长平台robots工具更新robots文件,显示抓取失败,多抓取几次,触发蜘蛛来抓取你的网站;
3)注意下抓取频次情况,如果抓取频次过低,可申请调整下抓取频次;
4)使用百度站长平台里的“资源提交-普通收录”工具,主动向搜索引擎提交网站链接。
相关阅读:
1、网站误封robots该如何解决;
2、网站robots文件是否要屏蔽JS和CSS文件;
3、Robots.txt文件要如何正确设置。
免责声明:本文所有图片、视频、音频等资料均来自互联网,不代表本站赞同其观点,内容仅提供用户参考,若因此产生任何纠纷,本站概不负责,如有侵权联系本站删除!邮箱:452315957@qq.com
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

